
Resources
MUStARD: Multimodal Sarcasm Detection Dataset

We release the MUStARD dataset which is a multimodal video corpus for research in automated sarcasm discovery. The dataset is compiled from popular TV shows including Friends, The Golden Girls, The Big Bang Theory, and Sarcasmaholics Anonymous. MUStARD consists of audiovisual utterances annotated with sarcasm labels. Each utterance is accompanied by its context, which provides additional information on the scenario where the utterance occurs.
MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations
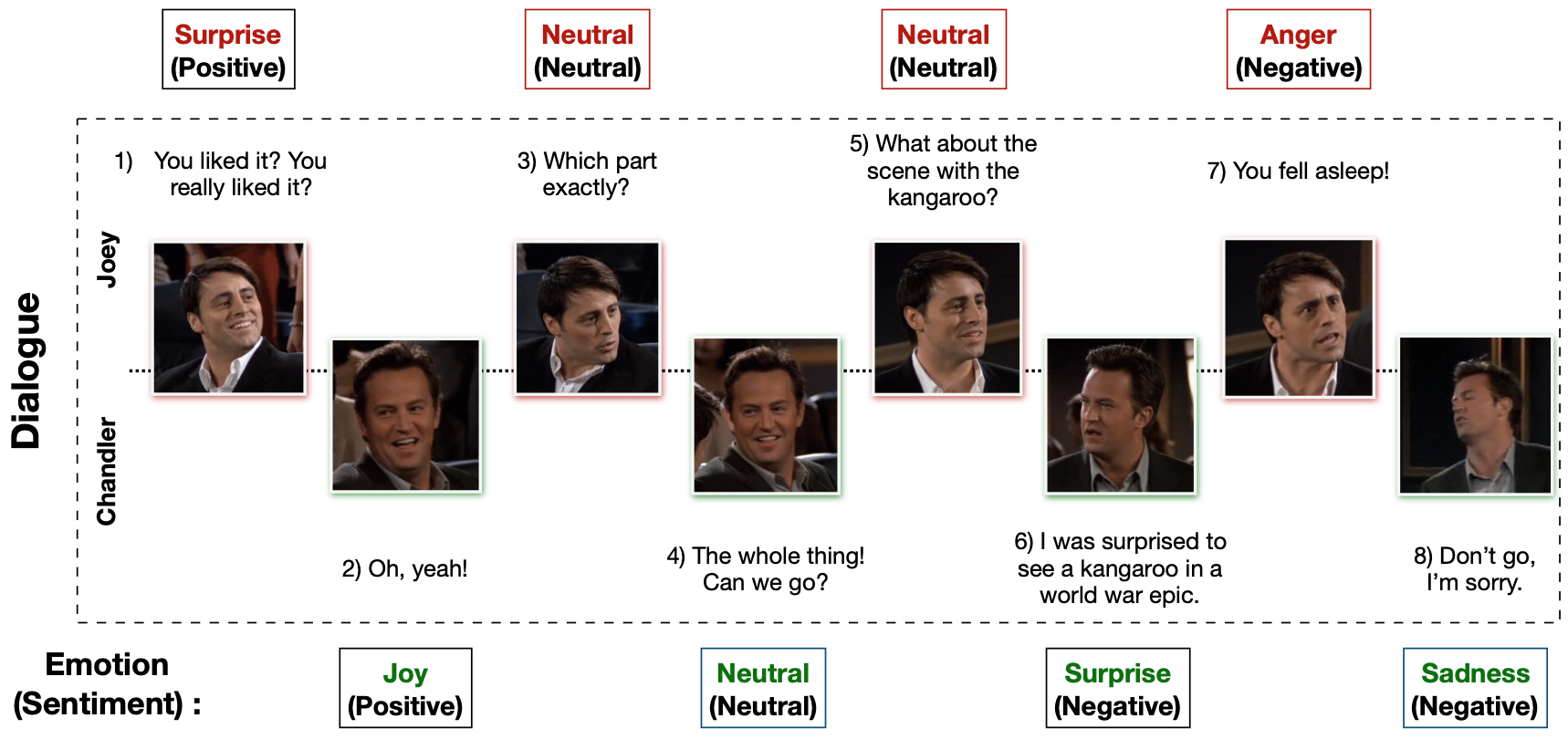
Multimodal EmotionLines Dataset (MELD) has been created by enhancing and extending the EmotionLines dataset. MELD contains the same dialogue instances available in EmotionLines, but it also encompasses audio and visual modality along with text. MELD has more than 1400 dialogues and 13000 utterances from Friends TV series. Multiple speakers participated in the dialogues. Each utterance in a dialogue has been labeled by any of these seven emotions – Anger, Disgust, Sadness, Joy, Neutral, Surprise and Fear. MELD also has sentiment (positive, negative and neutral) annotation for each utterance.